One of the biggest challenges when it comes to web applications is file storage. Here in Elemento 43, we have grown to prefer Amazon Web Services (AWS) and thus gravitate to Simple Cloud Storage (S3) every time we can because of its scalability, data availability, security and performance.
In one of our projects, we faced a rather strange behavior. One of the main features of this project involves uploading, sharing and managing PDF files and images through chat.
For the client-side, a web application in Angular was built. On the server-side, a REST API provides all the business functionalities through HTTP. All the user files are managed by this REST API using a database and S3.
End users are able to preview images and download any of their files. To manage the files in the frontend, we made use of metadata that is sent from the REST API, this metadata contains the name of the file, type, size, S3 URL, among others; The objects are displayed on the screen like this:
- PDF files appear as a box showing the name, clicking on the card will start the file download.
- The images are shown in a square (Preview) that when clicked, shows the complete image adjusted to the size of the window with a button to download the image as a file.
To view the images on the screen (both the preview and the full image), the image S3 URL is used, this URL is placed in the SRC property of the IMG tag, like this:
<img src="https://sample-bucket.s3....>
To download PDF files, an HTTP request is made to S3, this request generates a Binary Large OBject (BLOB) that is parsed into the correct file type on the user’s PC.
At the time of making the HTTP request to S3 to download an image, the following error was displayed:
Access to XMLHttpRequest at 'https://sample-bucket.s3...&X-Amz-SignedHeaders=host' from origin 'http://localhost:4200' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.It looked like a problem in the CORS policy setting, after checking the S3 settings, the CORS policy was correctly set already. Then the request headers were checked and a difference was noticed between the request to download a PDF file:
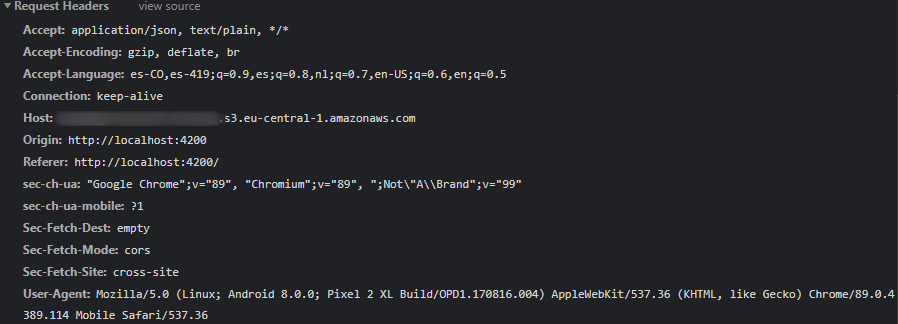
And the download of an image:

Something was not right.
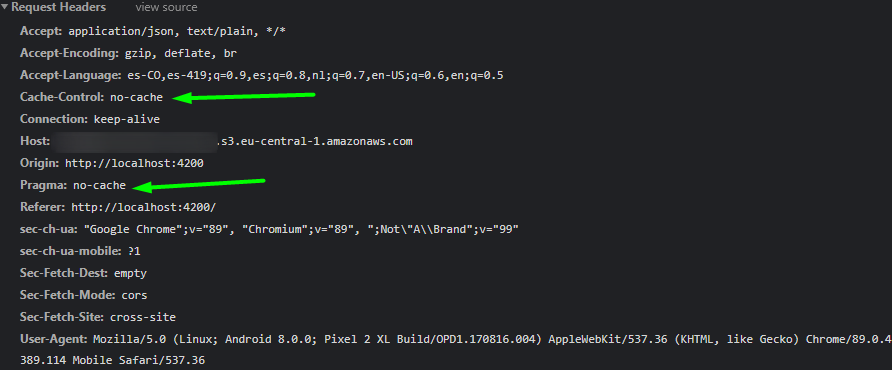
After an extensive call, several trials and errors, we found out that when the cache is disabled in the DevTools of the browser, the images were downloaded correctly. To avoid this issue, HTTP caching was implemented by adding a couple of headers. This prevents the usage of caching when getting files from S3.
- Cache-Control: no-cache
- Pragma: no-cache
Post by: Jair
Edited by: Amaury Ortega